Hard Example Mining
常规使用的有2种常见的困难样例挖掘(hard example mining)算法,1)用于优化SVM模型时使用 和2)对非SVM模型(存在loss)的模型使用。
在优化SVM的场景中,要维持一个训练样本工作集,训练过程在调整参数使得在工作集上收敛和调整工作集两个步骤间切换。调整工作集的标准是去掉一些已经被SVM模型正确分类的样本和添加一些被模型错误分类的样本。有论文已经证明这个过程最终会得到一个全局最优的SVM模型。
在非SVM模型的场景中,
训练算法开始于构造一个数据集:含有正样本数据和随机的负样本数据
再在得到的数据集上进行训练,
再将训练好的模型应用到其他未参与(未被随机选中)训练的负样本中,将判断错误的负样本数据(false positives)加入训练集,
重新对模型进行训练。
这种过程通常只迭代一次。没有证据表明这个过程最终会收敛。
在线困难样例挖掘(OHEM)算法:
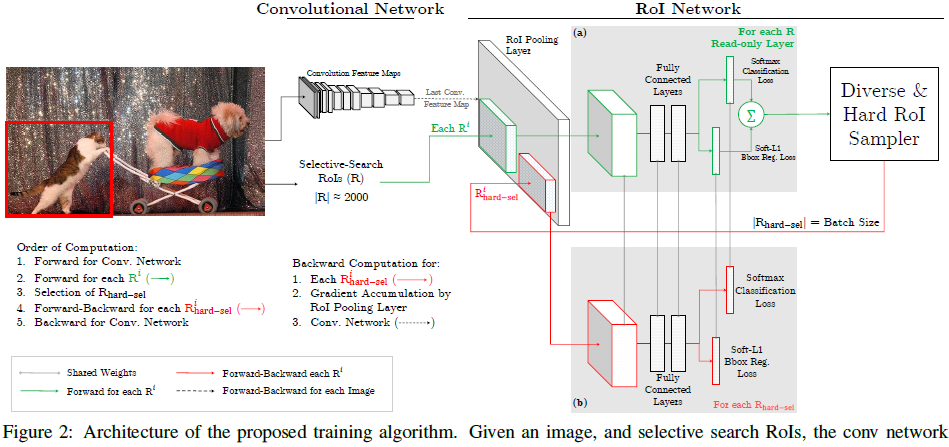
OHEM算法的核心是选择一些hard example作为训练的样本从而改善网络参数效果,hard example指的是有多样性和高损失的样本。
xxxxxxxxxx困难样例发掘(OHEM) alg:At SGD iteration t1. Image ---(conv) ---> Feature Maps2. RoIs via some selective method. 通过某种方式选择出RoIs3. 计算RoIs的损失losses4. 对RoIs依据losses进行排序 高loss对应着困难的RoI,从高到低选择B/N个loss最高的困难样例5. 利用选择的困难样例对网络进行训练
Notes
- 应用NMS(threshold = 0.7)来应对重叠度较高的困难样例
- 忽略了样本类间的比例。因为如果某一类较少,它的表现就会较差,loss较大,就会被选中用于训练。
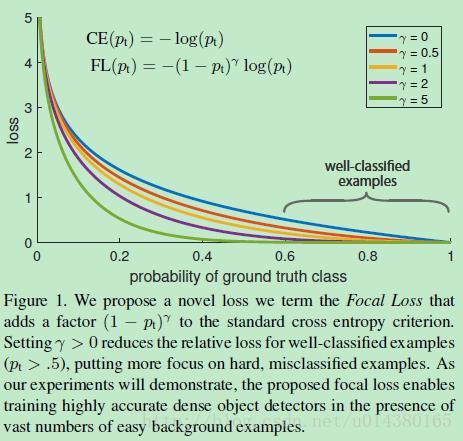
Focal Loss
根据论文作者的探查,在One-Stage Detector中由于较多的easy examples的loss之和overwhelm了hard example的loss(所以网络的学习就忽视 了hard examples)。
- 正负样本不均衡
- 正样本中easy examples vs hard examples不均衡。
所以就对困难样本loss加大权重